¿Cómo realizo la configuración?
Para realizar la configuración, verifica los siguientes procesos:
|
Paso
|
Acción
|
| ||||||||
 |
Establece valores mínimos y máximos, y el consumo de memoria para la instancia de SQL Server®.
Se recomienda establecer el límite mínimo y máximo de consumo de memoria para la instancia de SQL Server®. Por omisión, en la configuración estos límites no se encuentran establecidos, incluso el límite superior puede capturarse de acuerdo a los recursos del equipo. Se recomienda establecer estos valores para no presentar el escenario en donde el servicio de SQL tenga toda la memoria del equipo.
 2. Una vez dentro, haz clic en el botón derecho a las propiedades de la instancia.
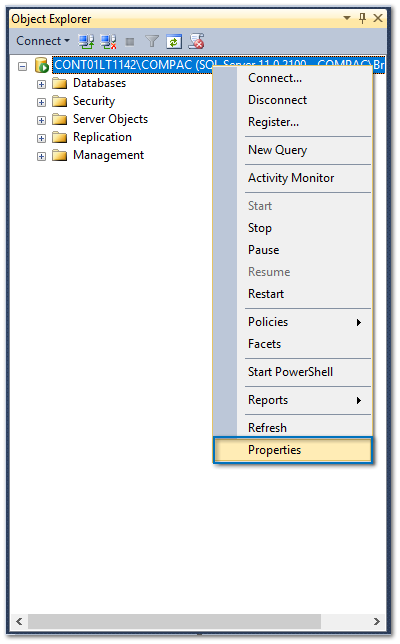 3. Se abrirá la ventana Server Properties, y en la sección de Memoria / Opciones de memoria, establece como valor mínimo: 512 y valor máximo 2048.
 |
| ||||||||
 |
Agrega archivos NDF para la base de datos tempdb.
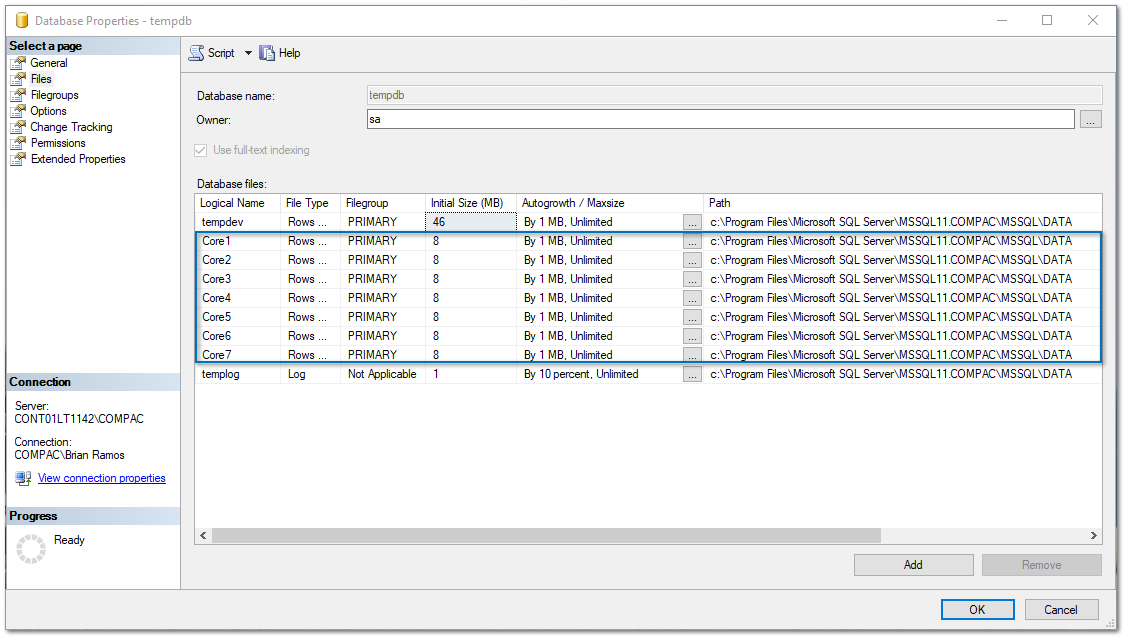
1. Primero, identificamos de cuántos núcleos (cores) dispone nuestra instancia de SQL Server®.
Para identificarlos, desde la ventana Propiedades del Servidor (Server Properties), selecciona la opción Procesadores (Processors):
2. Posteriormente, verificamos cuántos archivos NDF tiene la tempdb.
Para esto, ingresamos a las propiedades de la base de datos generales de la instancia tempdb, que se encuentra dentro de Databases / System Databases:
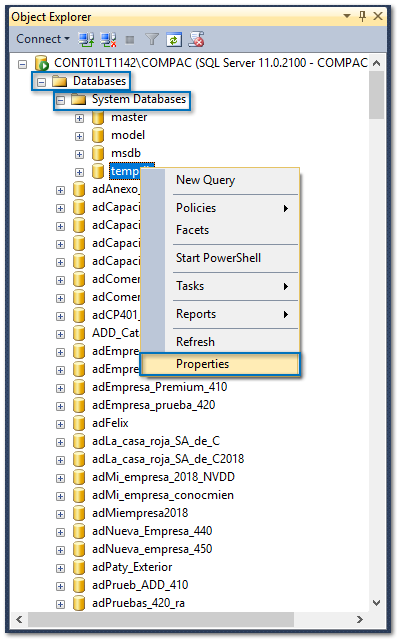 3. Se abrirá la ventana Database Properties, y selecciona la pestaña Files (Archivos) para visualizar los archivos NDF que se tienen.
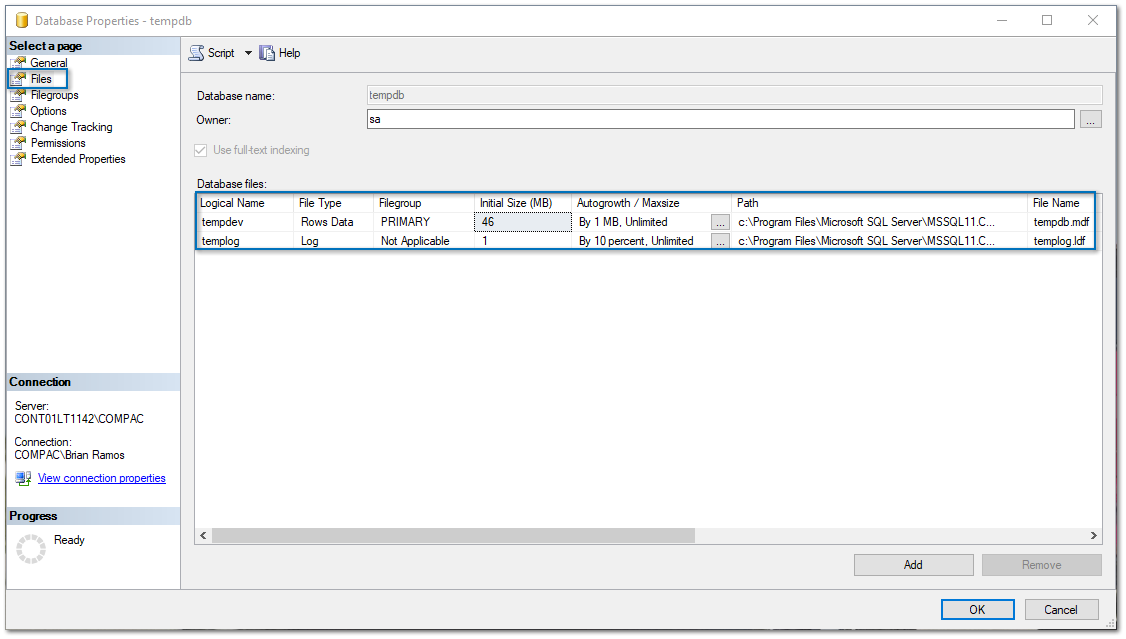
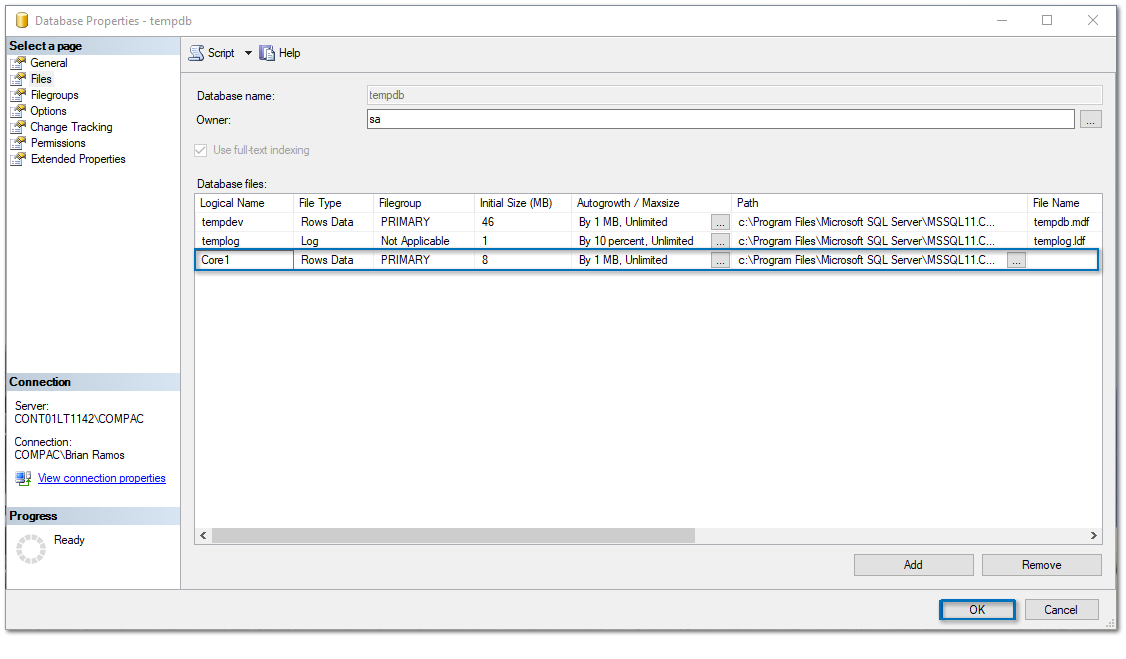
4. En este caso, como no tenemos más archivos pulsamos clic en el botón Add.
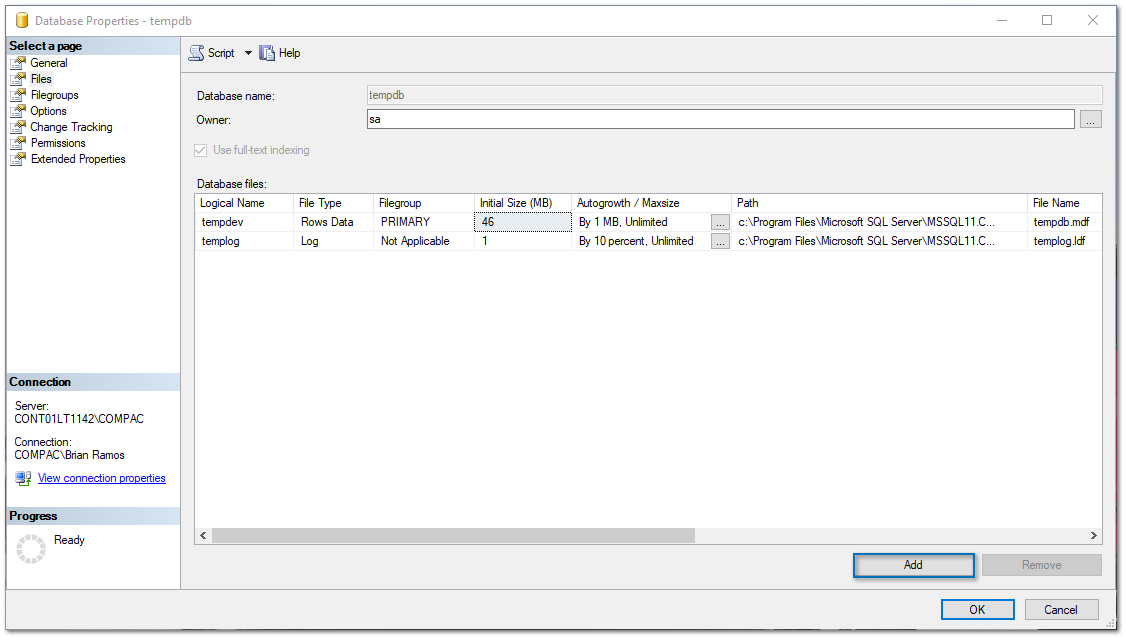 Por lo que se mostrará un renglón sin información.
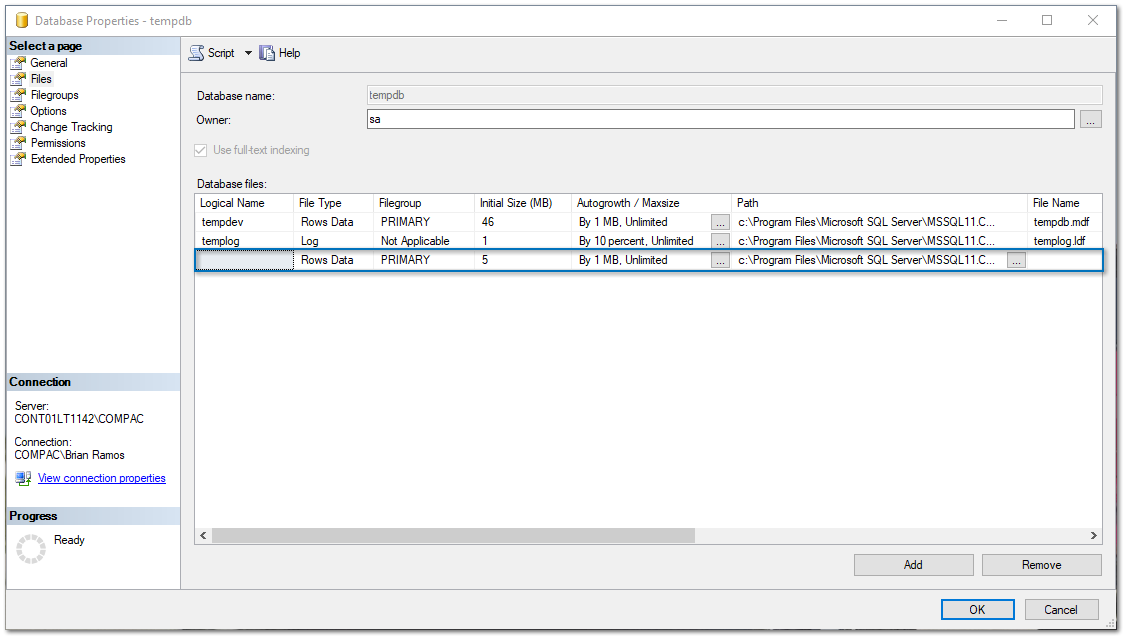 5. Después, haz clic en el nuevo renglón de la columna Initial Size, capturamos 8 MB y le asignamos un Nombre.
 |
| ||||||||
 |
Modifica a “Unlimited” el tamaño máximo de las bases de datos del ADD.
1. Para esto, ingresa a la base de datos del ADD y después en Properties.
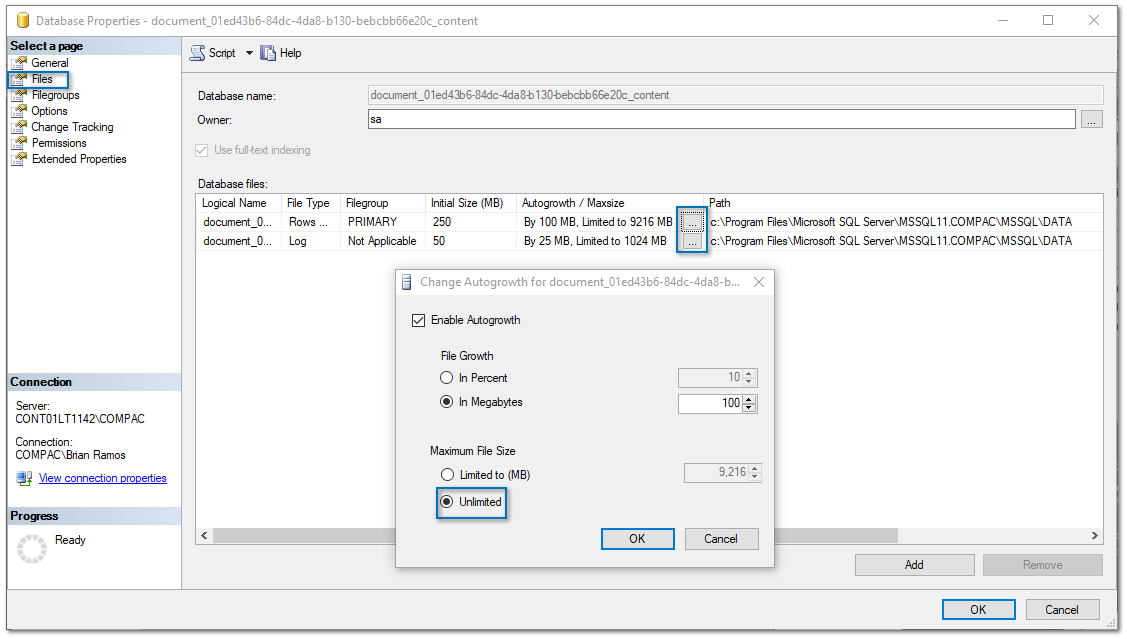
 2. Se mostrará la ventana Database Properties, luego haz clic en la pestaña Files (Archivos) y haz clic en el botón de los tres puntos de cada renglón, para cambiar a la opción a "Unlimited".
3. Posteriormente haz clic en el botón OK, para guardar los cambios.
|
| ||||||||
 |
Actualización de estadísticas de la base de datos.
Para obtener los comandos a utilizar, ejecuta el siguiente Query en cada base de datos (document y metadata).
Estos comandos ayudarán a optimizar la administración de la base de datos y mantener el mejor rendimiento de las consultas.
SELECT 'UPDATE STATISTICS ' + NAME FROM SYSOBJECTS WHERE xtype = 'U'
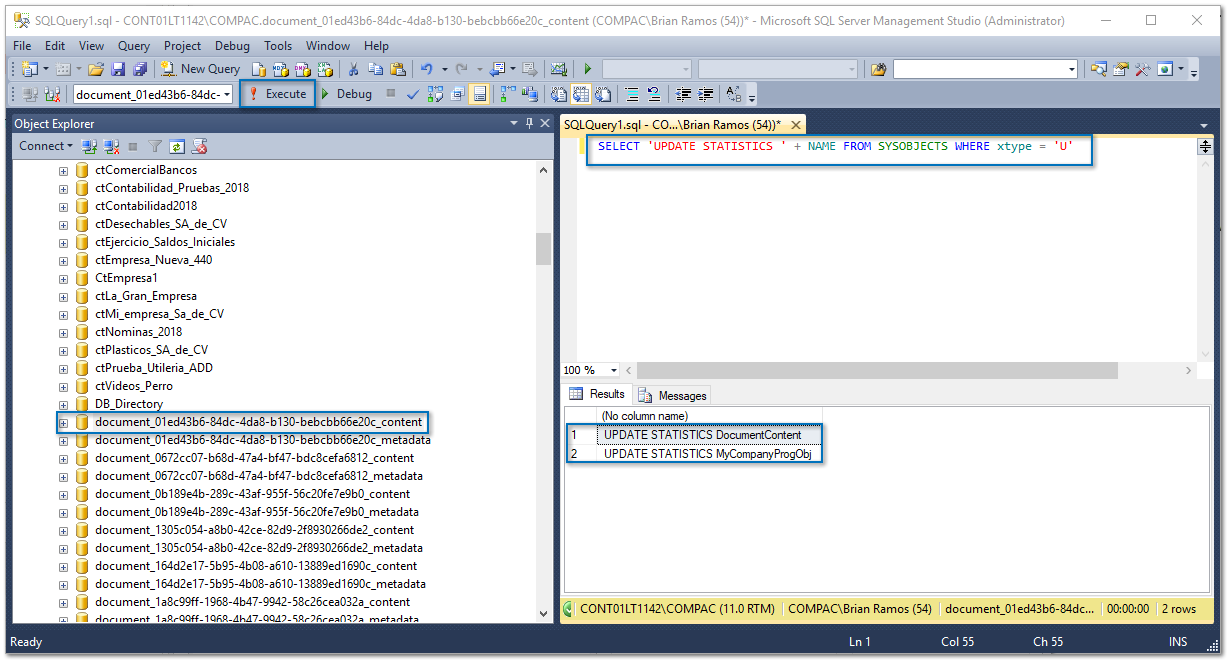 Después, haz clic en New Query (Nuevo Consulta), copia el resultado de la consulta anterior en una nueva ventana de comandos y ejecútalo:
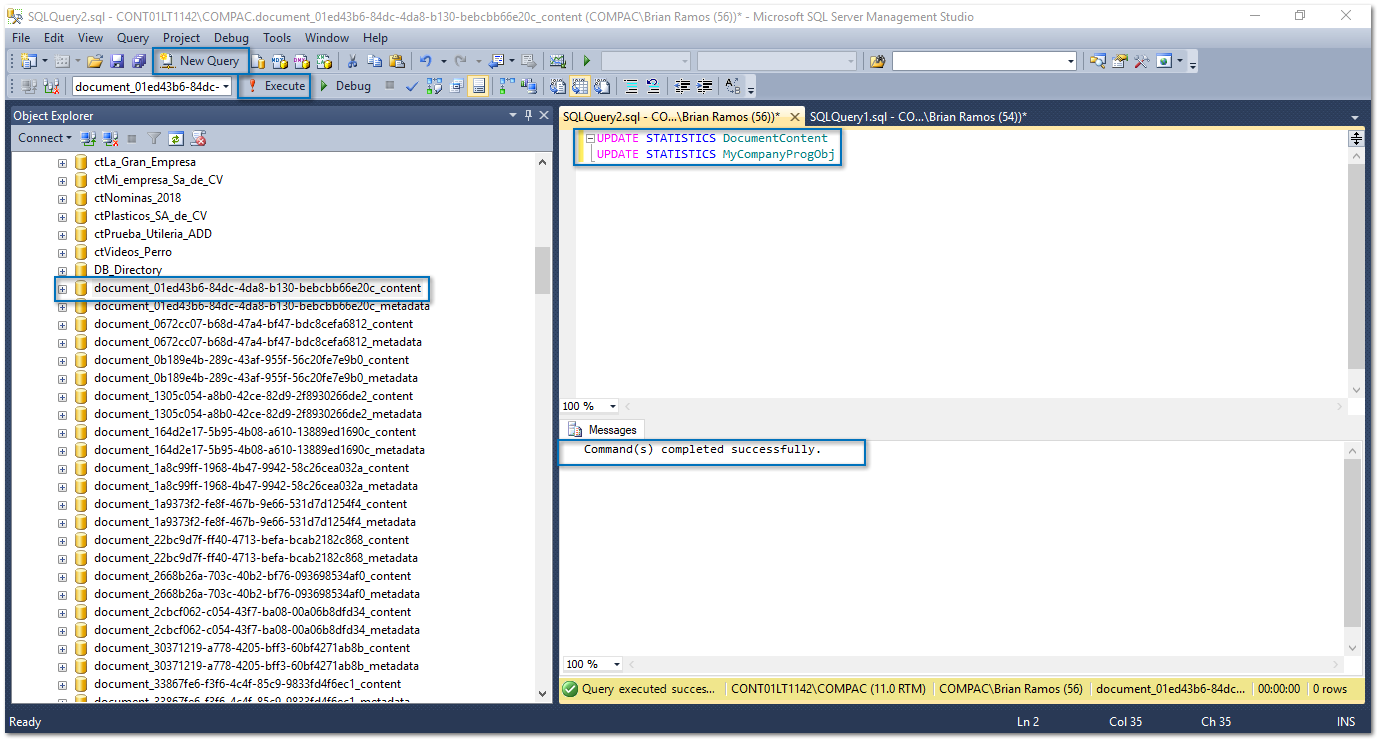
|
| ||||||||
 |
Reconstrucción de índices
Este proceso aplica para cada una de las bases de datos del ADD y será necesario ejecutar el siguiente comando en cada una de las bases (document y metadata) para reconstruir los índices:
select 'ALTER INDEX [' + i.[name] + ' ] ON [dbo].[' + t.[name] + '] REBUILD PARTITION = ALL WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)'
from sys.objects t
inner join sys.indexes i
on t.object_id = i.object_id
cross apply (select col.[name] + ', '
from sys.index_columns ic
inner join sys.columns col
on ic.object_id = col.object_id
and ic.column_id = col.column_id
where ic.object_id = t.object_id
and ic.index_id = i.index_id
order by col.column_id
for xml path ('') ) D (column_names)
where t.is_ms_shipped <> 1
and index_id > 0
order by i.[name]
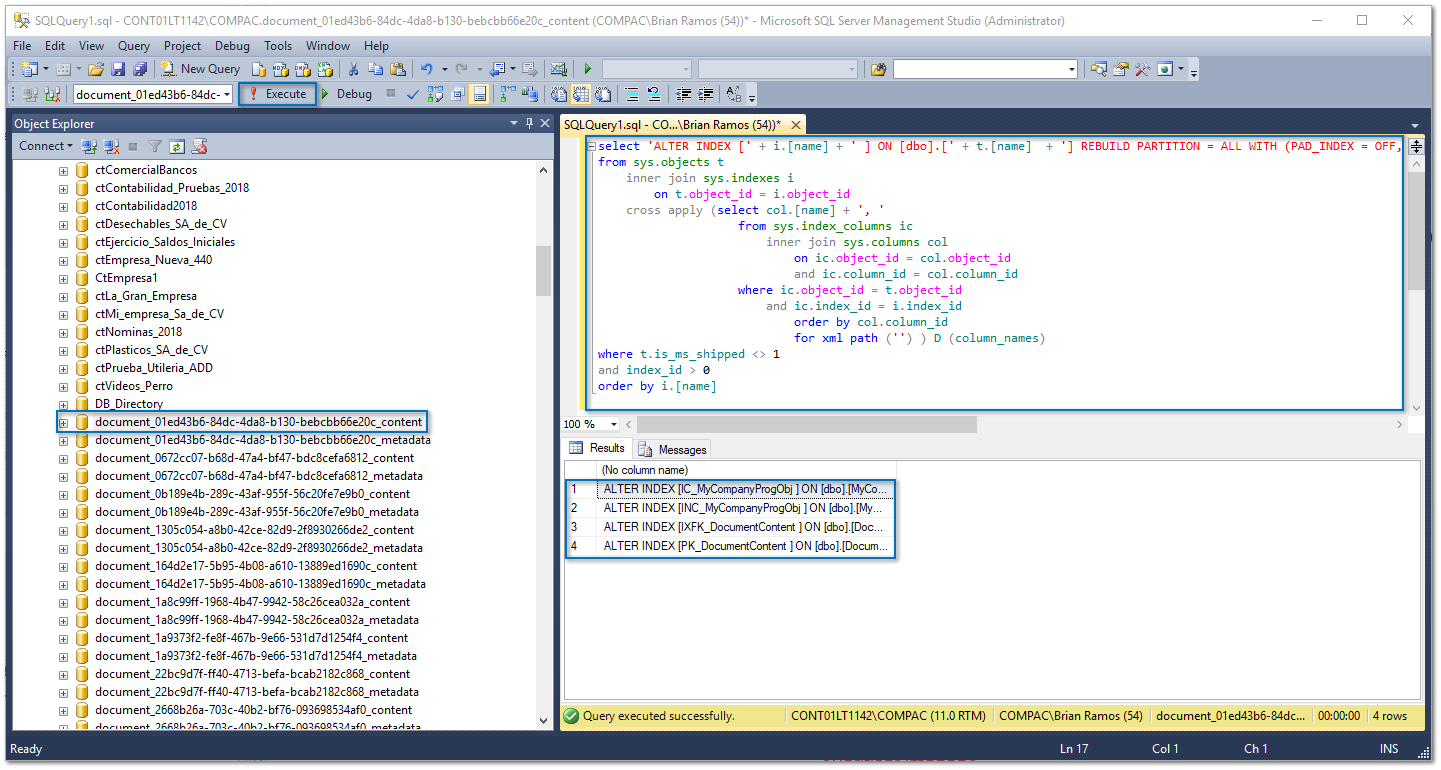 Haz clic en New Query (Nuevo Consulta), copia el resultado de la consulta anterior, y ejecútalo en una nueva ventana:
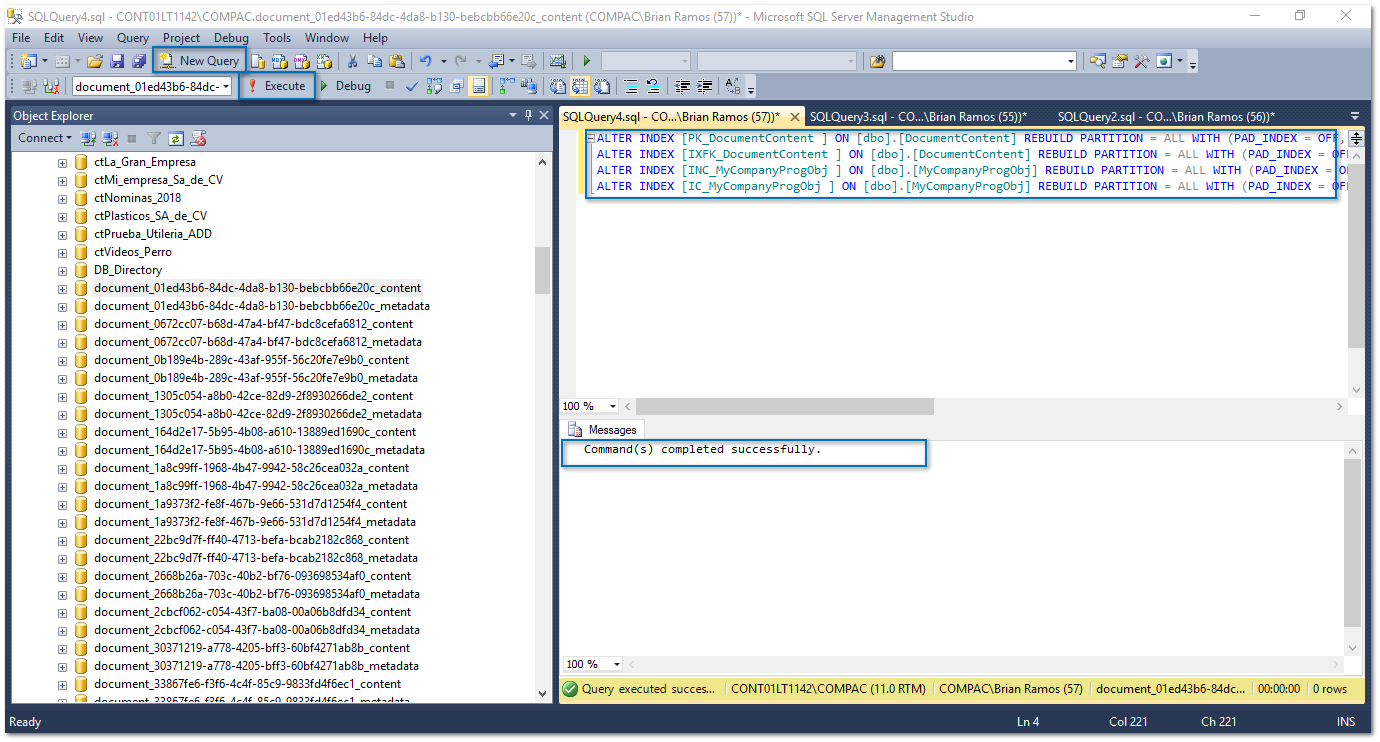
Para más información, podrás consultar esta liga de la Nota Técnica para el Mantenimiento de la BDD de los sistemas CONTPAQi®.
|
|